Optimizing a FastAPI service
16 Mar 2025From my experience working at Simpl.
One of things I’ve worked on in my time at Simpl is optimizing a backend service (Python FastAPI based) - the service used to evaluate user based on some rules and returned a response. As a part of evaluation we used ingredients we got from API post body request, called external db’s to get some data, external APIs to get some data, ran evaluation logic and returned a response. Crisp points on things that worked bring down p99 of the API from 150’ish ms to 75’ish ms - p90/95 were even lower ofcourse; Note that there are some more avenues I see to optimize this further, but got occupied with other priority work, hence did not spend time there, but will work again in near future.
- Firstly, for monitoring had integrated OTel telemetry metrics, and monitored critical functions used in API flow and checked which functions were taking most time to run. Also ensured OTel is not blocking main thread, rather running in background - by load testing before/after OTel integration on staging env.
- Increased load on the service i.e increasing ALBRequestCountPerTarget from 120 to 600 step by step and monitoring -> Not sure why did increasing load optimized rsponse time? Probably because of service warming up better?
- Decreased ECS task instances autoscaling limit from 4-70 to 4-30 as well as increasing scaling up/down time -> I think this helped ensure service is not frequently spinning up/down services as they too take time to get worked up when new task gets added, hence sustaining some load and if load is continuous for longer time then only scale up/down. As well as, changed ALB traffic routing to round robin (earlier it was different option)
- Cleaning up various parts of application code using singleton classes.
- API calls and functions defined in code, were already async, but one thing further helped; We called tables in dynamo to fetch some data points. To do so, we used async calls, but there is aioboto3 library as well, which does async much better. Had investigated if aioboto3 gives us connection pooling flexibility - Ref
- Load tested the service using k6 to keep track.
- Also ensured event publishing is happening by celery workers in background and not blocking main flow.
- Also brainstormed if increasing unicorn workers will help - but it won’t the workers simply run multiple instances (so say we use 4 workers in the service, effectively in an ECS task instance in rough words - there is further segregation of service code running in 4 processes, it ultimately depends on the underlying infra config how many cores CPU has and all, depends on if how we used reserved/spot infra [redacting some info] - but increasing this count may mostly result in change in throughput, and need not necessarily reduce latency),
- Ensured if the API calls made to db’s are in the same VPC (though it may not really make major difference),
- Checked with other teams if they call service with keep-alive TCP connections options (would reduce TCP handshake for every new connection/API call which is made)
- Worked with teams to have some of the relevant data sent in API post body itself, rather than us calling some external APIs to fetch the same data from them.
- Have to explore if caching (external via Redis or internal maintaining something in a data-structure - logic evaluation caching) fits in any usecase for similar requests we get + explore if the way we do evaluation in rules, can we fit multi-threading so that we find the satisfying rule(s) from all set after evaluation, and based on priority return the desired rule only, rather than o(n) iteration in single thread - although drawback is for every request all conditions would evaluate rather than ones which could’ve been evaluated first and exit. Also asses if rewriting service in Golang vs upgrading Py version to 3.14+ (to use GIL free compute on multiple cores) would help.
- Other application code changes: Used set{} than list[] in places which hold related data - so that access pattern is optimized (o(1) avg case). Segregated evaluation logic based on common attributes in rules, so that lesser rules are evaluated for related type of user request. Also if boundary conditions were breached, we exited quicker rather than running whole evaluation (basically tightened base conditions). Updated rules having NOT condition with help of previously segregated flow. We used expressions in rules, which were substituted with values used for evaluation with help of Template() library - internally it used Abstract Syntax Tree as seen, for ingredients used in rules - Unnecessary/redundant ingredients were trimmed down, so that internally the AST formed is smaller during evaluations. Each rule’s evaluation time was also benchmarked via time perf_counter functions. Etc.
- Snapshots:
-
Rule evaluation(s):

-
p99/p95/p90 metrics on OpenSearch.
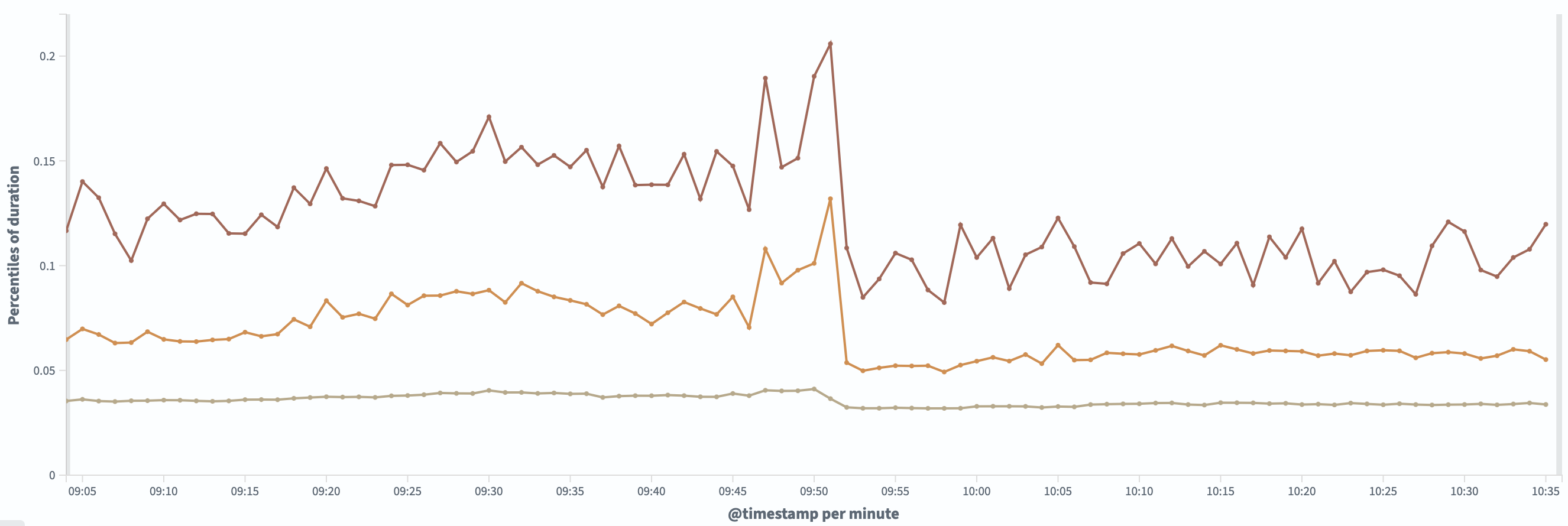
-
p99/p95/p90 metrics for one of the functions on Grafana (OTel)
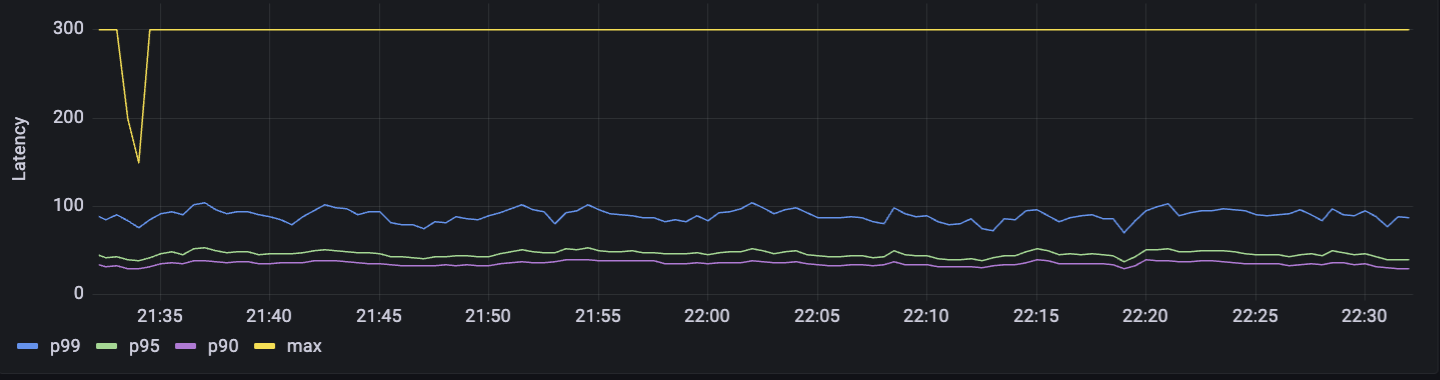
-