Optimizing Event parsing data pipeline
28 Jun 2025From my experience working at Simpl.
Also, got my blog published at Simpl’s engineering blog(s); For ref: Optimizing Event parsing data pipeline
The Data Platform team at Simpl is committed to delivering high-quality data with optimal latency to support critical business operations. Our ecosystem processes multiple batch and near real-time data pipelines that serve as the foundation for downstream teams including Analytics, Data Science, Fraud Detection, Risk Management and Business teams.
In this article, we will discuss about a critical data pipeline that serves as the backbone of our data flow— its past, present & future.
At Simpl, we have built our infrastructure around an event-driven architecture, which provides us with the necessary flexibility and scalability. To give a flavour around what happens behind the scenes, consider a real-world scenario:
A customer opens and browses through merchant mobile application (like Zomato, Swiggy, Myntra, etc.), and proceeds to place an order. During the checkout process, they can select Simpl’s “pay later” or “pay-in-3” option to complete their purchase.
Throughout this user’s purchase journey, a lot of action happens in the background to manage the Simpl payment experience.
Pre-Transaction Phase:
- Eligibility assessment to determine if Simpl payment option should be displayed to the user
- Risk evaluation and spending limit verification
- User interface configuration based on eligibility status
Transaction Initiation:
- User selects Simpl as their preferred payment method
- Transaction request is initiated and validated
- Real-time credit limit check and approval process
- Payment authorization and merchant confirmation
Transaction Processing:
- Transaction execution and completion status tracking
- Payment settlement between merchant and Simpl
- Transaction success or failure determination
Post-Transaction Activities:
- Automated communication dispatch (SMS/email) for transaction confirmation or failure notifications
- User’s Simpl app account update with debited amount and remaining credit limit
- Transaction history recording and receipt generation
- Merchant settlement and reconciliation processes
- Credit utilization tracking and repayment schedule updates
Each of these interactions generates specific event data that helps us monitor the entire payment ecosystem and ensure a seamless user experience.
{
"event_id": "017309f7-c126-44f8-9333-1896e5ecd2df",
"event_timestamp": "2025-06-01T07:14:13.185474522Z",
"event_name": "UserTransactionCompletedEvent",
"user": {
"id": "17ztr78q-9ad5-753f-aa98-f1e6g5543c98",
"phone_number": "9999999999"
},
"transaction_details": {
"total_amount": 56000,
"merchant": "Myntra",
"payment_status": "successful",
"failure_reason": null
},
"payment_mode": "simpl-pay-later",
"version": "1.0.0"
}
The event data is later relayed to downstream systems and pipelines that perform ETL operations and enrich the silver layer tables - maintained by Data Platform team which we will discuss next.
High Level overview & components of the pipeline
- Kafka:
- As discussed earlier, we have events generated by the producer systems which are published by them to Kafka - precisely AWS MSK, as we use AWS as our cloud provider at Simpl.
- On a daily basis, over 300M+ events are produced by the systems and processed by the data pipeline.
- Events are segregated into appropriate Kafka topics based on their properties, eg: user related events in one topic, communication related events in another topic, etc.
- Our Kafka consumers which run on ECS round the clock, consume these published events and store them in Amazon S3 for persistent storage. Based on the recent trends, over 1TB+ JSON data is dumped in S3 comprising of 2M+ individual file objects. These metrics continue to grow as our user base expands and transaction volume increases.
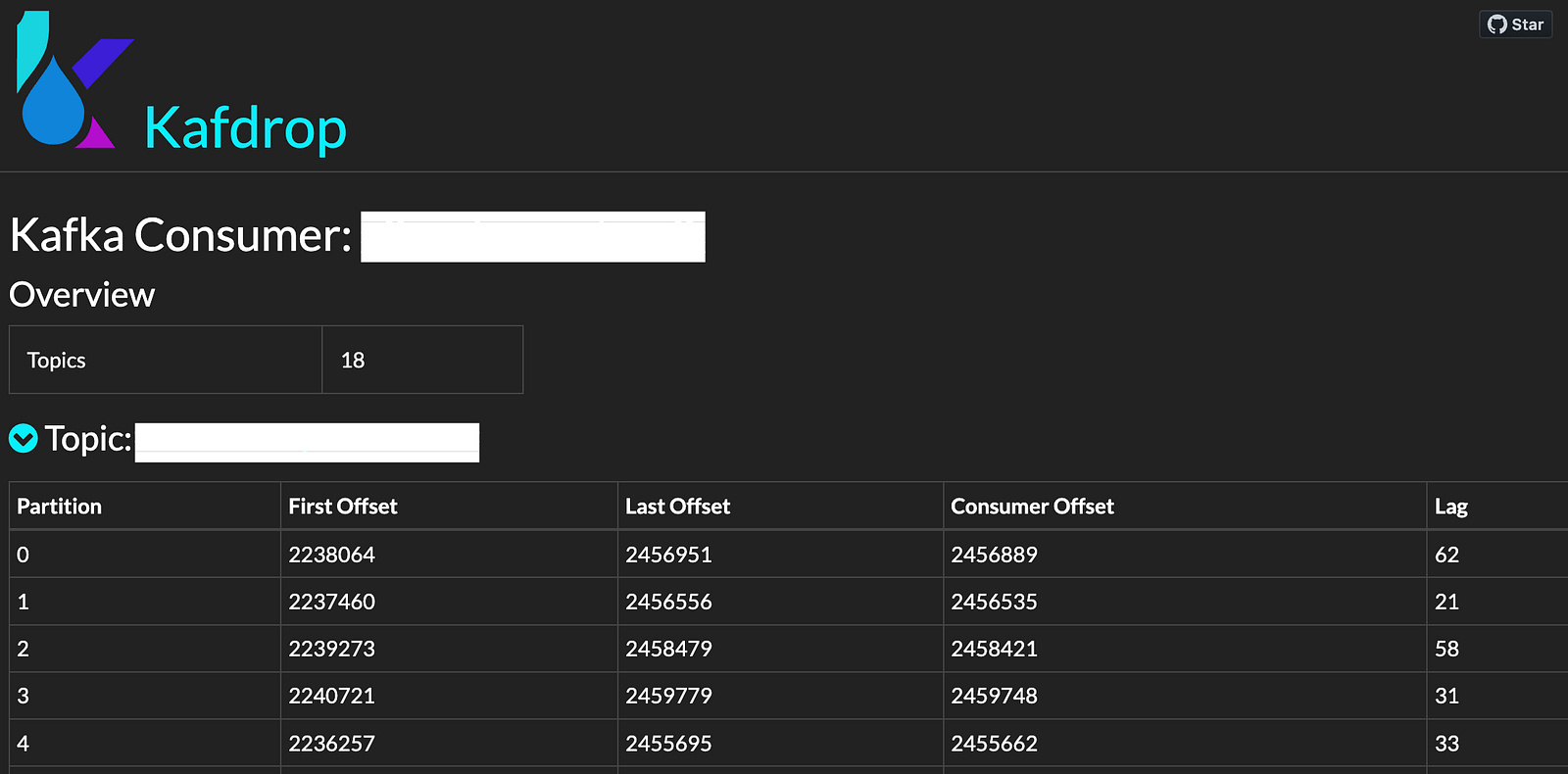
- Airflow:
- We use Apache Airflow as our primary workflow orchestration platform. It runs event parsing jobs performing Extract, Transform, and Load (ETL) operations on the raw event data accumulated in S3.
- It involves retrieving raw events from S3, parsing and transforming the data according to business rules, and storing the processed data in multiple formats including Parquet and CSV files.
- Finally, the processed data is loaded into over 400+ tables defined in AWS Redshift or partitioned external tables defined in Databricks.

- Databricks:
- We use Databricks as our unified analytics platform that serves multiple critical functions in our data ecosystem.
- As discussed, we define external tables over the processed parquet files and use them to enrich our silver/golden data layer.
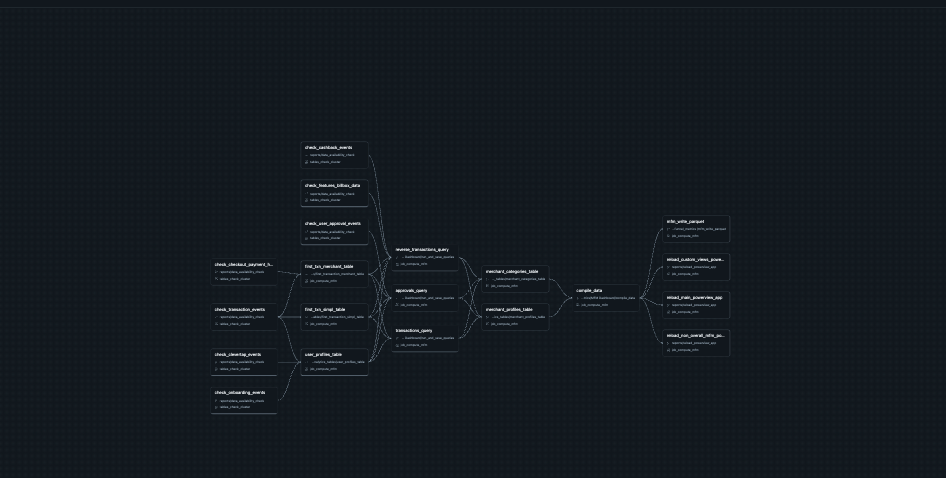
At a 50,000ft view, it may seem like a simple event parsing pipeline, but the same pipeline used to run for over 8Hrs in the past to enrich the silver layer. The team worked upon optimising the entire pipeline and brought down the runtime to an hour.
The Past: Legacy Pipeline Architecture
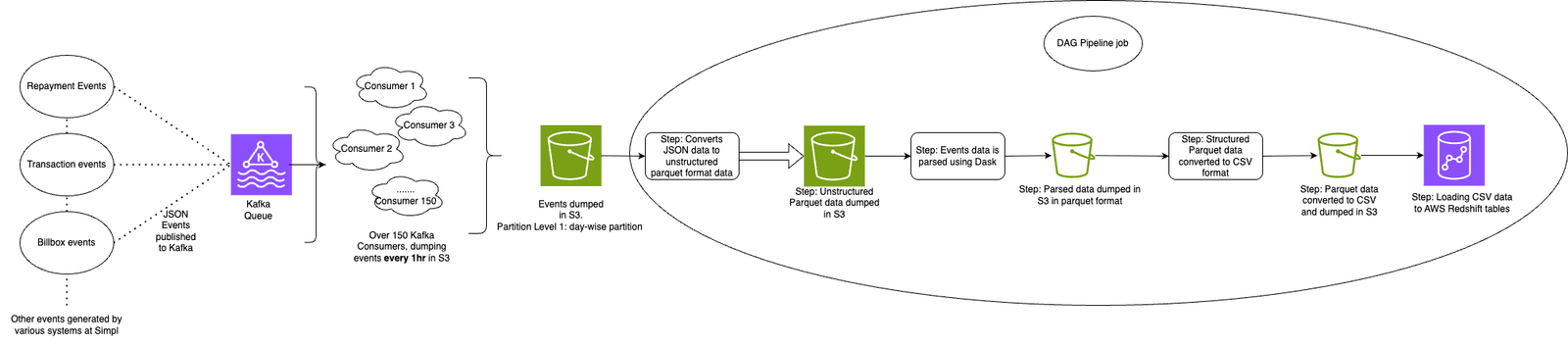
- Kafka and the Consumer Configuration
- Events were published in different Kafka topics. It included events of dissimilar themes as well being published in same topic.
- We operated 150 instances of Kafka consumers that were responsible for consuming events from Kafka and dumping raw data to S3 storage.
- The consumers wrote data to S3 based on two threshold conditions, whichever was reached first:
- The accumulated event files exceeded 500 megabytes in size in buffer (or)
- The time buffer exceeded one hour since the last write operation.
- Storage Organization
- The folder structure in S3 utilized one-level partitioning scheme where raw events were dumped:
- Level 1 partitioning was organized by day, creating separate folders for each date. All the raw events data was dumped on the given date.
- This partitioning strategy resulted in S3 paths structured like: event_date=2023_01_02/data.json.gz
- The folder structure in S3 utilized one-level partitioning scheme where raw events were dumped:
- ETL Workflow
- Airflow orchestrator scheduled jobs to perform ETL operations on events data.
- As seen in the architecture diagram, the operations involved:
- Step 1: Initial Format Conversion - We converted raw JSON gzip event data into unstructured Parquet format and stored it in a designated S3 folder.
- Step 2: Data Parsing and Structuring - We parsed the unstructured data to extract only the necessary information according to predefined business rules and schema definitions using distributed computing framework in tandem with open-source jsonschema library for parsing. This cleaned and structured Parquet data was then stored in another S3 folder.
- Step 3: CSV Conversion - The clean Parquet data was converted to CSV format and stored in yet another folder.
- Step 4: Data Warehouse Loading - The CSV files were loaded into corresponding Redshift tables, making the processed data available for consumption by downstream teams. The data powered different categories of tables in the ecosystem like: Redshift, Glue, Redshift Spectrum, etc.
- We leveraged Airflow’s ECSOperator to execute parsing jobs within ECS environments calling distributed computing nodes configured on EC2 instances in cluster to handle the computational workload.
- We performed data deduplication operations directly within Redshift tables.
Pain Points
- Large number of small files problem - Based on the kafka consumer thresholds, there were a larger number of small files generated. This would later become a significant performance bottleneck in our processing pipeline as the data would increase.
- Suboptimal Deduplication - We were deduplicating data in our Redshift tables. There remained opportunities for optimization in how and when deduplication was performed.
- High Infrastructure Costs - Operating more than 150 consumer instances continuously contributed substantially to our infrastructure costs, without proportional performance benefits.
- Latency in near-realtime-data availability - Since the Kafka consumers dumped data based on when either memory buffer or time buffer threshold was breached - the current thresholds were high which introduced significant delta between file writes which was not consumable for nrt tables.
- Inefficient partitioning strategy - The partitioning scheme was based on current_day/event.json.gz and this was inefficient. As when parsing jobs ran for multiple events within a single day, each job would redundantly scan through all event data present in that day’s folder, select only the specific events it was designed to process, and then perform its operations. This resulted in unnecessary I/O operations and processing overhead.
- Multiple file conversions - The pipeline required multiple file format conversions (raw JSON to unstructured Parquet to structured Parquet to CSV) throughout the ETL flow, significantly increasing the overall runtime and storage requirements.
- Unnecessary Event Consumption - Producer systems published diverse set of events to shared Kafka topics without proper thematic segregation. Events that didn’t require parsing or table loading were mixed with critical events, forcing consumers to process all of them. For example, user-related events were published alongside communication events instead of being properly isolated into dedicated topics (user-topic, communication-topic).
The complete pipeline required approximately 8 to 9 hours to process a full day’s worth of data. As our data volume increased over time, the runtime also increased proportionally, creating significant impacts on downstream systems that depended on timely data availability.
The Present: Optimized Pipeline Architecture
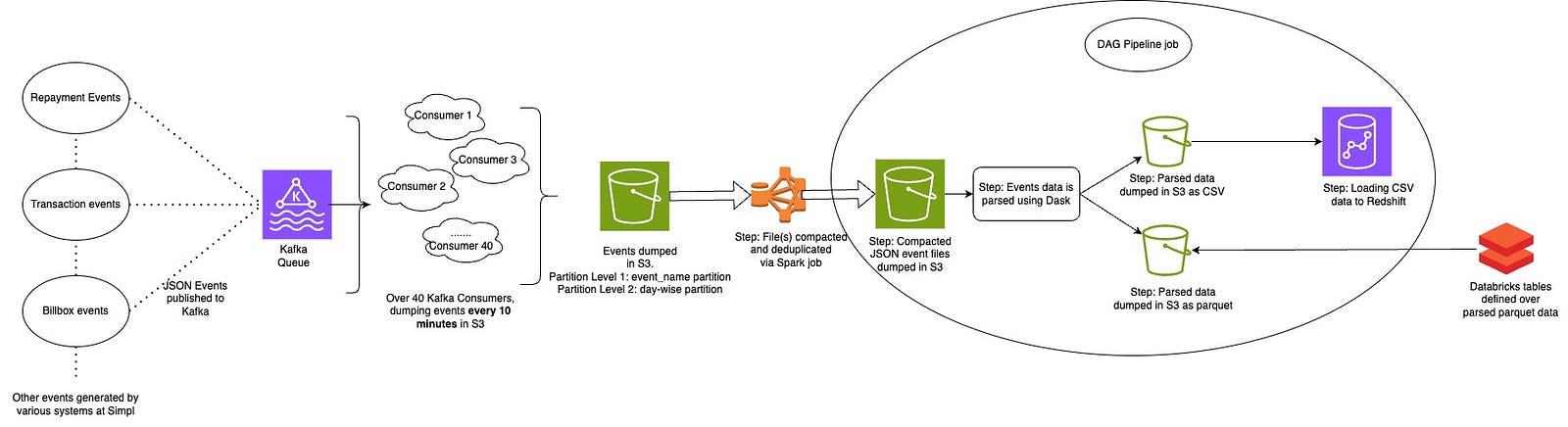
We addressed the identified pain points through a pipeline redesign over the time.
- Kafka and the Consumer Optimization
- We cleaned up our Kafka topics with better segregation of similar themed events. This helped in consumers consuming only relevant data from the required topics.
- We also introduced data enrichment and masking capabilities in our consumer to apply transformation rules and security policies in real-time, handling PII data with care.
- The revised consumer configuration writes data to S3 when either of two threshold conditions is met:
- The accumulated event files exceed 10 megabytes in size (or)
- The time buffer exceeds 10 minutes since the last write operation.
- Although this configuration did not decrease the number of files, it significantly reduced near-real-time data latency. We also built external tables on top of the this data to serve some of our near-realtime use cases.
-
We decreased the number of running consumers from 150 to 40 after testing with various numbers.
- Addressing Small Files Problem
- The increased number of smaller files presented new challenges for our distributed computing nodes like scheduler stability and worker termination.
- To resolve these issues, we developed a dedicated Spark job for file compaction. Since our consumers generate new files every 10 minutes throughout the day, we designed it to ensure it’s not impacting files being dumped by the running consumers.
- The compaction job ensures that the optimal number of properly sized files is available for the ETL operations. We also migrated our data deduplication logic into the compaction job remove duplicates and ensure our pipeline delivers records in exactly once manner.
- We integrated Databricks into this ecosystem to run the Spark compaction job. Our compaction process typically completes within 20 to 25 minutes, after which our event parsing jobs trigger.
- Improved Partitioning Strategy
- We redesigned our S3 folder structure partitioning to optimize data access patterns:
- Level 1 partitioning is now organized by event name, creating top-level folders for each event type.
- Level 2 partitioning is organized by day, creating date-based subfolders within each event type folder.
- This results in S3 paths structured as: transaction_events/event_date=2023_01_02/data.json.gz
- This partitioning change enabled parsing jobs to directly access data corresponding to specific events for the day thereby optimising processing time.
- We redesigned our S3 folder structure partitioning to optimize data access patterns:
- Streamlined File Format Conversion Process
- We eliminated unnecessary intermediate steps in our format conversion process.
- The new pipeline converts raw JSON directly to structured Parquet and CSV formats, eliminating the intermediate step of creating and storing unstructured Parquet data in S3.
- This change reduces both storage requirements and processing time while maintaining data quality and integrity.
- Infrastructure Updates
- As discussed earlier, reducing the number of consumer instances from 150 to 40 after testing the consumer lag, data latency and resource utilization helped in optimal use of resources.
- We also upgraded our Airflow from version 1.x to 2.x, updating internal libraries to their latest stable versions, and optimizing our ECS and EC2 configurations for better performance and cost efficiency.
- Databricks Integration
- We integrated Databricks as a central component of our ecosystem and defined comprehensive tables within the platform. This includes - external table, managed tables, delta tables, etc.
- The underlying objective of this integration is to consolidate data scattered across different systems into a single, unified platform. This improves data accessibility, reduces complexity for downstream consumers, and provides a foundation for advanced analytics and machine learning capabilities.
- Performance Improvements and Results: The comprehensive optimizations we implemented resulted in a dramatic reduction in pipeline runtime from 8-9 hours to approximately 1 hour. This improvement had significant positive impacts on downstream systems and drives business growth.
What’s Next: Future Optimization Roadmap
- We plan to leverage evolving capabilities of spark streaming or flink to enhance our pipeline further with the growing data.
- We plan to sunset AWS Redshift and migrate our ecosystem to Databricks to maintain system hygiene better and have a central data warehouse.
- We are developing our golden data layer architecture, which will help downstream systems consume data more efficiently.
Key Takeaways
This journey highlights several key principles for large-scale data pipeline optimization:
- Right-sizing of Infrastructure
- Data Partition Strategy Matters
- Choosing relevant file format for optimal storage
- Tool Selection for Specific Use Cases
- Eliminating Unnecessary Steps in processing
- Minimising data shuffling
- Central Platform Consolidation
“Excellence is never an accident. It is always the result of high intention, sincere effort, and intelligent execution”