Cleanup of a bulky Postgres table
20 Jul 2025From my experience working at Simpl.
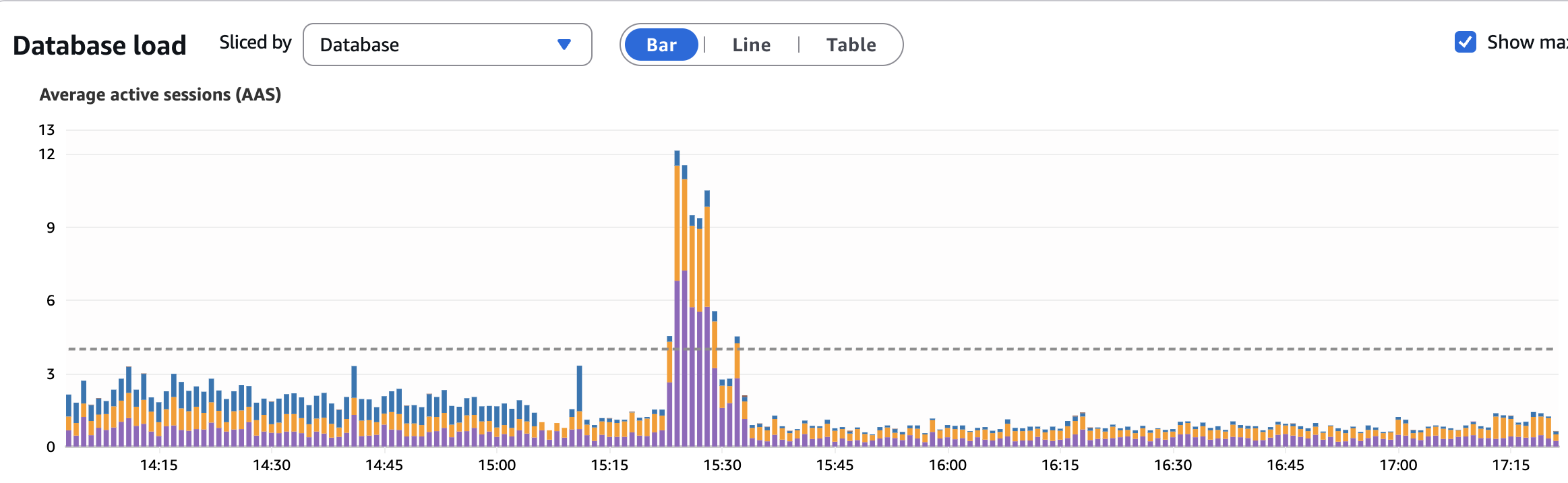
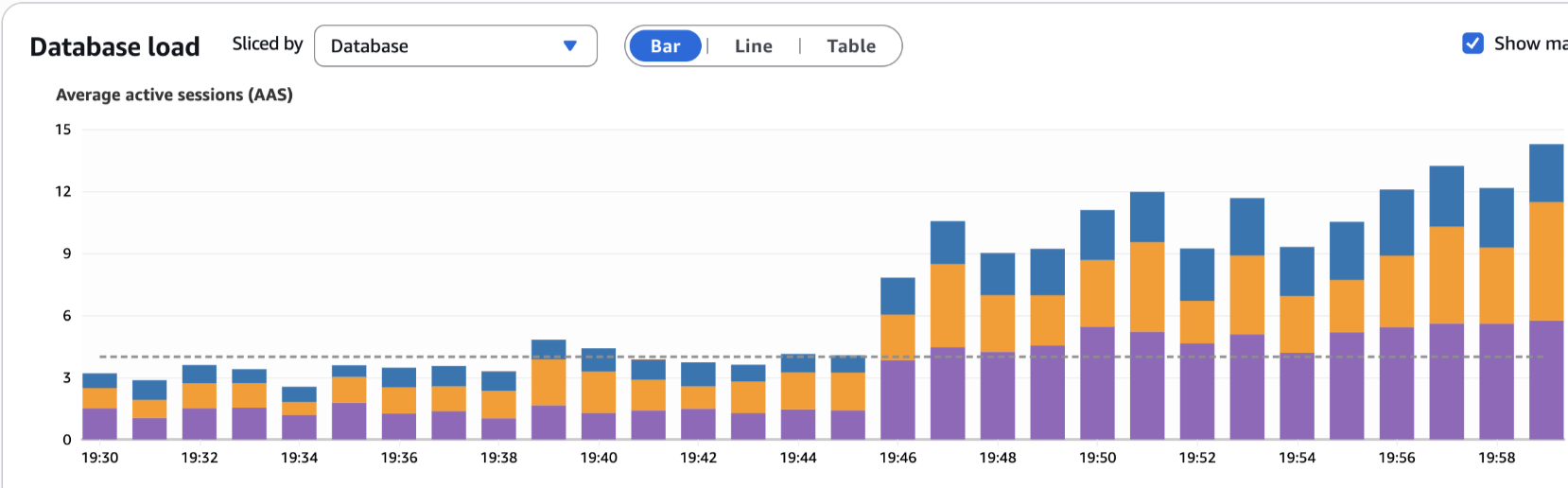
I worked on an interesting task along with the devops team of cleaning up a bulky legacy Postgres table in the db, which was causing cluster-wide performance degradation (Eg: Auto-vacuum processes were triggering frequently, locking table and impacting writes across the entire database cluster).
Example:
 The table was loaded with real-time data from a Kafka consumer running round the clock.
It had over ~ 1.6B rows having roughly a month of data; ~ 600GB total size; Of which indexes size ~ 125GB, toast size ~ 125GB. A daily batch job was running to delete data older than 30 days. Command which it used:
The table was loaded with real-time data from a Kafka consumer running round the clock.
It had over ~ 1.6B rows having roughly a month of data; ~ 600GB total size; Of which indexes size ~ 125GB, toast size ~ 125GB. A daily batch job was running to delete data older than 30 days. Command which it used: DELETE FROM <tableNameX> WHERE created_at < '<current_time_minus_thirty_days>' on the writer postgres instance - and this is not an effective command (discussed later)
Query to get metadata of all tables in db:
SELECT
t.table_schema || '.' || t.table_name AS table_full_name,
COALESCE(c.reltuples, 0) AS estimated_rows,
pg_size_pretty(pg_total_relation_size(quote_ident(t.table_schema) || '.' || quote_ident(t.table_name))) AS total_size,
pg_size_pretty(pg_relation_size(quote_ident(t.table_schema) || '.' || quote_ident(t.table_name))) AS table_size,
pg_size_pretty(pg_indexes_size(quote_ident(t.table_schema) || '.' || quote_ident(t.table_name))) AS indexes_size,
pg_size_pretty(pg_total_relation_size(quote_ident(t.table_schema) || '.' || quote_ident(t.table_name)) - pg_relation_size(quote_ident(t.table_schema) || '.' || quote_ident(t.table_name))) AS toast_size
FROM
information_schema.tables t
JOIN
pg_class c ON c.relname = t.table_name
JOIN
pg_namespace n ON n.nspname = t.table_schema AND n.oid = c.relnamespace
WHERE
t.table_schema NOT IN ('information_schema', 'pg_catalog')
AND t.table_type = 'BASE TABLE'
ORDER BY
pg_total_relation_size(quote_ident(t.table_schema) || '.' || quote_ident(t.table_name)) DESC;
Crisp points learned & strategy:
- Post discussing with teams - it was found concrete requirement of data was only for 1 week, hence we could proceed with deleting data older than 7 days. Expected downtime was communicated in advance.
- Key PostgreSQL Concepts
-
By default, PostgreSQL is a single-node OLTP (Online Transaction Processing) database, with: one primary (writable) instance & no built-in read replicas. In real-world deployments, PostgreSQL is often extended like below. This setup is implemented using streaming replication or tools like: Amazon RDS/Aurora for PostgreSQL (managed reader endpoints), etc.
Role Description Writer (Primary) Handles all write operations: INSERT,UPDATE,DELETEReader (Replica) Handles read-only queries. Replicated from primary. - Table Bloat:
- When rows are updated or deleted in PostgreSQL, the old versions are not physically removed immediately. This leads to table bloat.
- What Happens Internally:
- PostgreSQL uses MVCC (Multi-Version Concurrency Control).
- An UPDATE creates a new row version (tuple) and marks the old one as dead.
- A DELETE marks the row as dead, but doesn’t remove it.
- These dead tuples still occupy disk space.
- Over time, with many updates/deletes, the table grows in size (bloats), even if the row count doesn’t.
- Impact:
- Slower sequential scans and index usage
- Increased I/O due to reading bloated pages
- Sluggish performance for frequently updated tables
- Auto-vacuum:
- Auto-Vacuum is PostgreSQL’s background process that automatically cleans up dead tuples to control bloat and maintain visibility maps.
- What Happens Internally:
- PostgreSQL tracks how many tuples are updated or deleted.
- When thresholds are crossed (autovacuum_vacuum_threshold + fraction of table), the autovacuum daemon kicks in. It: Scans the table and visibility map, Removes dead tuples (if not visible to any active transaction), Updates the free space map (FSM) and visibility map
- If it’s doing an aggressive freeze (e.g., nearing vacuum_freeze_max_age), it may take heavier locks or consume more I/O.
- Notes:
- Typically holds an ACCESS SHARE lock, which doesn’t block reads/writes.
- On very large tables, it can compete with application queries for CPU and I/O.
- If not tuned properly, autovacuum may lag behind, leading to excessive bloat or even transaction wraparound issues.
- TOAST (The Oversized-Attribute Storage Technique):
- TOAST handles storage of large data types like text, bytea, or jsonb that exceed a threshold (typically ~2KB).
- What Happens Internally:
- When a row contains a large column (e.g., a big text field), PostgreSQL:
- Compresses the value (if possible)
- If still too large, stores the value in a separate TOAST table
- The main table stores a pointer to the TOAST data
- The TOAST table is created automatically, one per main table.
- TOAST data is stored in chunks (usually 2KB) in the TOAST table.
- When a row contains a large column (e.g., a big text field), PostgreSQL:
- Cleanup Complexity:
- VACUUM and autovacuum must also manage the TOAST table.
- Large updates or deletes may leave dead TOAST tuples as well.
- If TOAST cleanup is missed or delayed, it can cause hidden bloat.
-
- Coming back, existing deletion strategy using
DELETEwas not effective.- DELETE operations don’t reclaim disk space immediately
- Creates massive amounts of dead tuples (bloat)
- Triggers aggressive auto-vacuum cycles
- Auto-vacuum locks table during cleanup
- Impacts performance of concurrent writes
- TOAST data cleanup is particularly expensive
- Solution Options Evaluated
- Option 1: New Table with Different Name
- Minimal downtime
- Risk: Consumer services might miss updating table name
- Rejected due to operational risk/backward compatibility in workflows.
- Option 2: Recreate with Daily Partitions
- Same table name maintained
- 1-3 hours downtime as copying data to new table, dropping old table, renaming new table with old table name.
- Data builds back over 7 days
- Option 3: Drop and Recreate (Selected)
- Was discussed and ensured losing old data is fine, and reloading fresh data.
- 10-20 minute downtime
- No backfill required
- Minimal impact
- Step 0: Readers (eg: Analytics workflows) and writers (eg: Kafka consumer) to the table were stopped temporarily, turned on later once the activity was complete
- Step 1: Rename existing table
ALTER TABLE tableNameX RENAME TO tableNameX_Old; - Step 2: Create partitioned table
CREATE TABLE tableNameX ( event_id uuid NOT NULL, event_timestamp timestamptz, event_type varchar(50), .... PRIMARY KEY (event_id, event_timestamp) ) PARTITION BY RANGE (event_timestamp); - Step 3: Configure pg_partman
-- Create parent partitioning structure SELECT partman.create_parent( p_parent_table => 'public.tableNameX', p_control => 'event_timestamp', p_type => 'native', p_interval=> 'daily', p_premake => 365 ); -- Set retention policy UPDATE partman.part_config SET infinite_time_partitions = true, retention = '6 days', retention_keep_table = false WHERE parent_table = 'public.tableNameX'; - Step 4: Create indexes
-- No need to create explicit index on event_timestamp and event_id as PostgreSQL automatically creates a unique B-tree index for the primary keys CREATE INDEX tableNameX_user_id_idx ON public.tableNameX (user_id);
- Option 1: New Table with Different Name
- Key Benefits of Partitioning Approach:
- Automatic partition management: pg_partman creates future partitions via cron
- Efficient data removal: DROP PARTITION vs DELETE (instant vs hours)
- Query transparency: Applications query main table; PostgreSQL routes to correct partition
- No bloat accumulation: Old partitions dropped entirely
- Predictable performance: Each partition remains manageable size
- No manual intervention: Retention automatically enforced
- Others:
- DELETE is not suitable for time-series data at scale
- Creates bloat instead of freeing space
- Triggers expensive auto-vacuum cycles
- Partitioning is essential for large time-series tables
- DROP PARTITION is instantaneous
- No bloat, no vacuum needed
- pg_partman simplifies partition management
- Automatic partition creation and built-in retention policies
- No custom scripts needed
- Partition constraints are important
- Once partitioned, you can add partitions but not remove partitioning
- Plan partition strategy carefully
- DELETE is not suitable for time-series data at scale
- Metrics monitored:
- Memory/CPU usage
- Running queries, Auto-vacuum frequency, etc.
- Query performance
- Disk space reclamation
- Alternative Approaches (Not Used)
- pg_repack:
- Would reclaim space but lock table
- Not suitable for high-write tables
- Temporary solution only
- TRUNCATE:
- Would lose all data
- Not viable for production
- Manual partition management:
- Error-prone
- Requires custom scripts
- pg_partman is superior
- pg_repack:
Impact: Decrease in load (blue)