Debugging silent connection leak in service
30 Nov 2025From my experience working at Simpl.
- Some brief: We had a monolith Ruby-Rails service which was fairly complex having frontend/backend/kafka consumers related components. It interacted with various postgres RDS tables, external APIs, Kafka, RabbitMQ cluster(s). It was deployed on ECS, running over 30 tasks in parallel.
- Issue: Our alerts (Cloudwatch+Zenduty) notified us of an unusual drop in database connection counts (these were constant-workload tables by the way). The service appeared healthy on the surface as well as the frontend UI component of the service was working fine, but there were issues underneath.
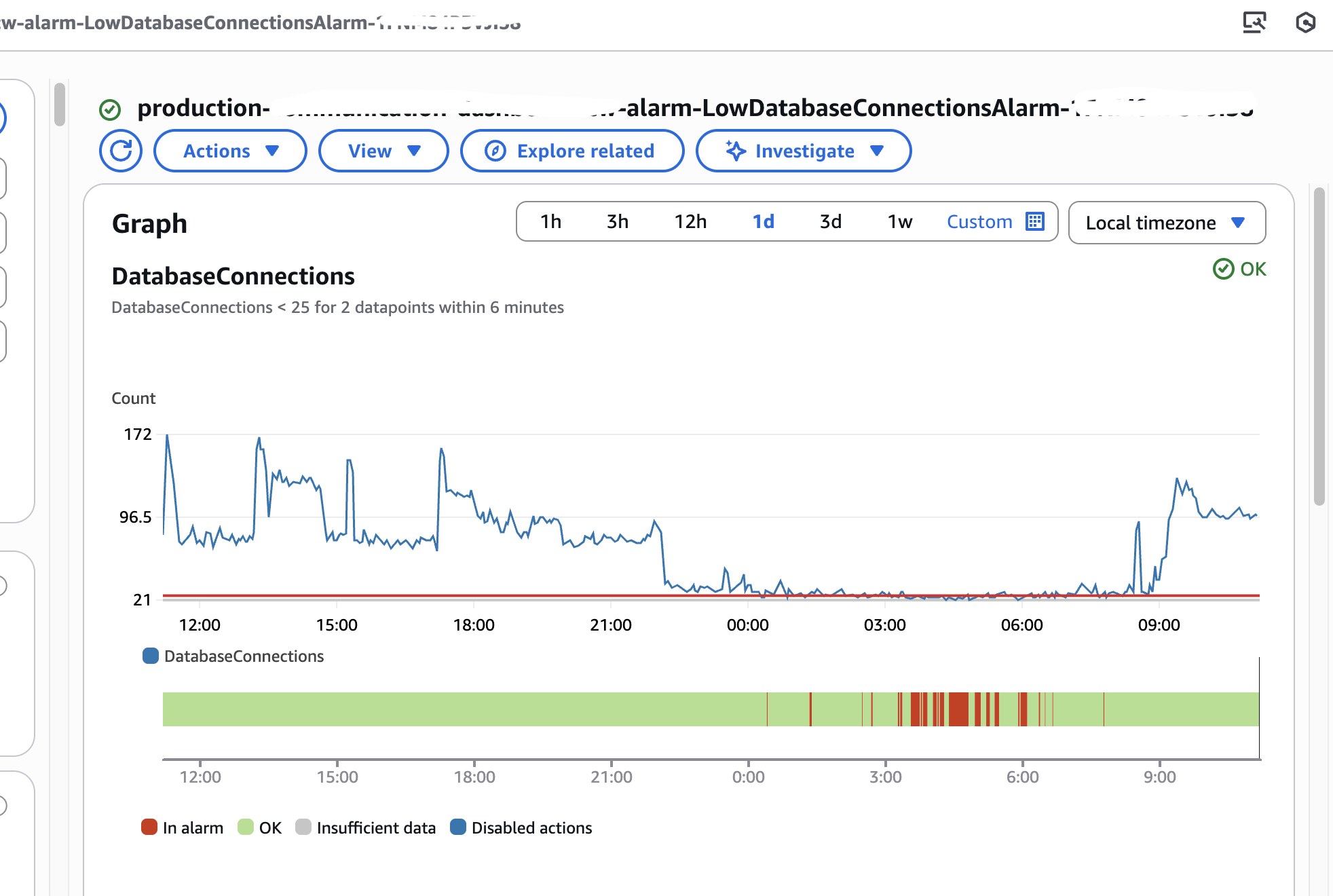
- Debugging issue:
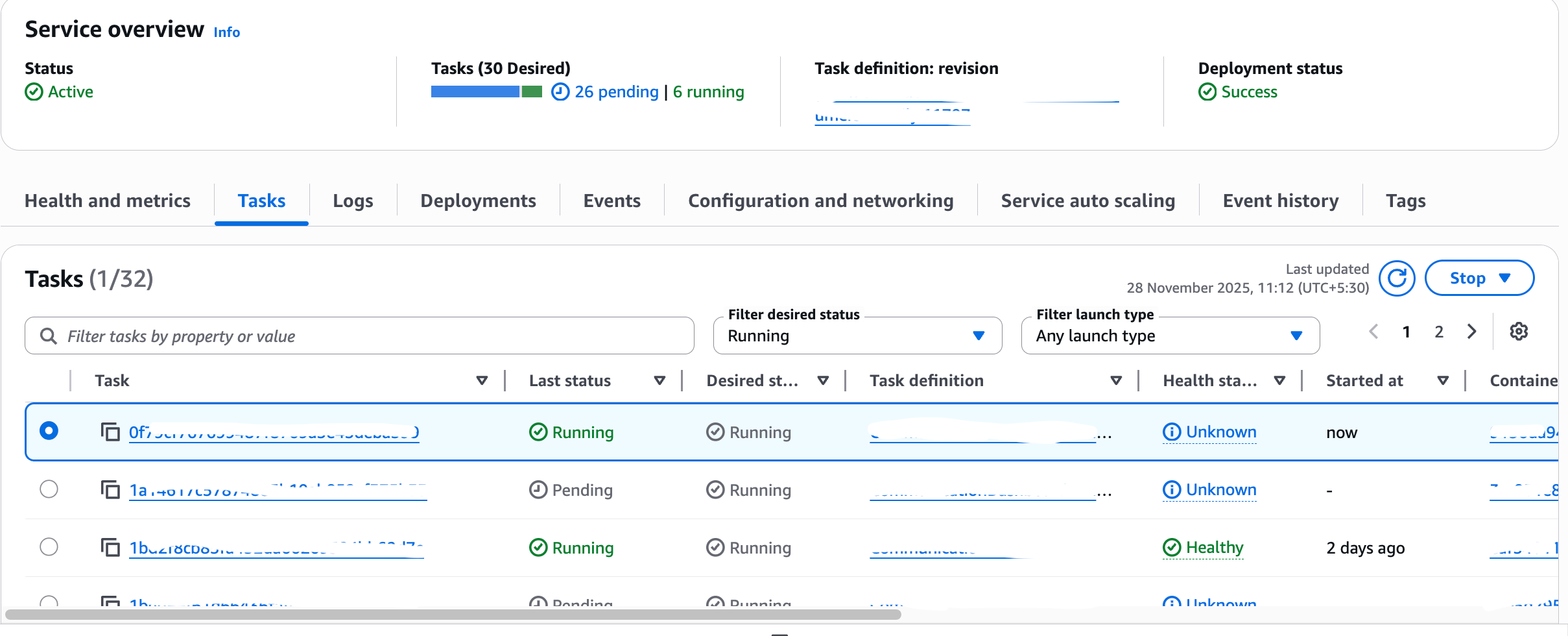
- We were looking at various metrics, one of them being the ECS task status, where we discovered 80%+ containers were caught in a restart loop, continuously failing and being restarted by ECS. Only some containers remained stable and running. Since it was an internal service, traffic volume was relatively low, so few surviving containers were able handle the incoming load without any obvious performance degradation. Had the traffic been high, the service would have definitely impacted.
- Tracing backward from the database connection drop, we checked the service logs and it showed connection errors, but not to our primary databases, instead failed connections to a RabbitMQ cluster that we had deprecated few days back.

- As we traced back, the codebase still contained initialization code that attempted to establish connections to the old RabbitMQ cluster during container startup. It probably wasn’t cleaned up properly since the logic is buried in legacy modules.
- So this was the presumed issue flow: ECS launches a new container task -> Ruby application begins initialization -> Legacy module attempts to connect to deprecated RabbitMQ cluster -> Connection fails (cluster no longer accessible) -> Failure triggers application crash or health check failure -> ECS detects unhealthy container and restarts it -> DB connections drop triggering alerts -> Cycle repeats indefinitely.
- Few running containers were pretty much a ticking time-bomb, that would’ve also failed anyways.
- Graceful degradation is important, but sometimes, your code should fail-fast.
- We removed the loose connections from the codebase & cleaned up the old code. Also improved handling during connection initializations and later deployed all changes.
- We were looking at various metrics, one of them being the ECS task status, where we discovered 80%+ containers were caught in a restart loop, continuously failing and being restarted by ECS. Only some containers remained stable and running. Since it was an internal service, traffic volume was relatively low, so few surviving containers were able handle the incoming load without any obvious performance degradation. Had the traffic been high, the service would have definitely impacted.